the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 08 Jun 2020
| 08 Jun 2020
Robust regional clustering and modeling of nonstationary summer temperature extremes across Germany
Meagan Carney
Holger Kantz
We use sophisticated machine-learning techniques on a network of summer temperature and precipitation time series taken from stations throughout Germany for the years from 1960 to 2018. In particular, we consider (normalized) maximized mutual information as the measure of similarity and expand on recent clustering methods for climate modeling by applying a weighted kernel-based k-means algorithm. We find robust regional clusters that are both time invariant and shared by networks defined separately by precipitation and temperature time series. Finally, we use the resulting clusters to create a nonstationary model of regional summer temperature extremes throughout Germany and are thereby able to quantify the increase in the probability of observing high extreme summer temperature values (>35 ∘C) compared with the last 30 years.
- Article
(6055 KB) - Full-text XML
- BibTeX
- EndNote





Extremes in temperature have lasting affects on human health (Gasparrini et al., 2017), power consumption (Thornton et al., 2016; Bartos et al., 2016; Burillo, 2019), biodiversity, and ecosystem services (Bellard et al., 2012; Balvanera et al., 2013). As extreme events occur in the tails of probability distributions, studying them allows us to make predictions of rare, and more catastrophic, weather events. For this reason, recent climate literature has become more focused on extreme event statistics (Brown et al., 2008; Cheng et al., 2014; Christidis et al., 2011; Finkel and Katz, 2018).
Modeling extreme events typically involves fitting a generalized extreme value (GEV) probability distribution to these data under the assumption that the parameters of this distribution do not change in time or are “stationary” (Coles, 2001). Climate variability has resulted in challenges to these assumptions. Steady increasing trends in the mean air temperature have been observed worldwide (Hansen et al., 2010; Wergen and Krug, 2010) and have been attributed to anthropogenic green house gas emissions (Erkwurzel et al., 2017; Hansen et al., 2012; Christidis et al., 2011). With the continued warming trend and recurring heat waves sweeping across Europe (Kyselý, 2002; Schär et al., 2004), most recently occurring in the summers of 2015, 2018, and 2019, the need for nonstationary modeling for accurate extreme temperature prediction has become more apparent (Christidis et al., 2015; Hasan et al., 2013; Hamdi et al., 2018; Rahmstorf and Coumou, 2011). We cite Caroni and Panagoulia (2016), Gao and Zheng (2018), and Hamdi et al. (2018) for examples of nonstationary extreme value modeling; however, there are numerous other examples in the literature. Nonstationary adaptations are particularly important for countries that are less equipped to handle these high temperature events, such as Germany (Tomczyk and Sulikowska, 2018; Kosanic et al., 2019).
Along with nonstationary modeling, there is the need to create regional models of extremes as policy making and governmental response are most influenced when extreme weather events are predicted on a larger scale. With the introduction of machine-learning techniques such as maximized modularity algorithms (Newman, 2006; Duch and Arenas, 2005) and spectral clustering (Hastie et al., 2008; Luxburg, 2007) in many scientific areas including genetics, physics, computer science, and neuroscience, among others (Guimera and Amaral, 2005; Treviño et al., 2012; Zscheischler et al., 2012; Azencott et al., 2018), we are better equipped to deal with large data which provide a more accurate, global understanding of networks. These techniques are particularly useful for dense clusters, such as those observed in climate data where meteorological towers are gridded; networks that are affected by many external factors; and where obvious divisions are unknown.
Recently, spectral clustering methods have been shown to provide reasonable clustering results for climate networks defined by a set of time series (Carney et al., 2019); however, these methods may fail when networks with high intra-cluster similarity are considered. We expand on the methods of Carney et al. (2019) by introducing a weighted kernel approach based on a spectral view of the network that allows for more reliable clustering of dense climate networks where simple k-means methods cannot be reliably implemented. This method provides a robust regional clustering of summer temperature time series from meteorological stations throughout Germany. We show that these regions are both time invariant and equivalent over summer temperature and precipitation time series. We use these clusters to create nonstationary regional models of temperature extremes. Our results show a significant increase in the probability of returns for high summer temperature values (>35 ∘C) for each region in Germany.
This paper is outlined as follows. Section 2 is broken into three parts: Sect.2.1 contains details on the chosen subset of data; Sect. 2.2 provides relevant background on clustering methods and a detailed description of the clustering algorithm; and Sect. 2.3 provides relevant background on extreme value modeling and details on the methods used for regional modeling of summer temperature extremes. Section 3 is broken into two parts: Sect. 3.1 contains results on the clustering algorithm applied to summer temperature and precipitation time series taken from the stations across Germany; and Sect. 3.2 outlines the extreme value results on the station level and their incorporation into the regional models formed from the clustering outcome. Section 4 is a brief summary of the paper containing future work motivated by the results in this paper.
2.1 Data
The data in this analysis were taken from the Deutscher Wetterdienst Climate Data Center (DWD CDC, 2018a), which contains climate records from stations across Germany. We use three data sets from the DWD in total: hourly temperature values from 1960 to 2018 (measured in Celsius), hourly precipitation values from 1995 to 2018 (measured in millimeters), and daily precipitation amounts from 1960 to 2018 (measured in millimeters). All three data sets are used in clustering analysis, although only the hourly temperature data set is used for extremes analysis. We choose two precipitation data sets because hourly precipitation values are not available across Germany before 1995 and daily precipitation values do not provide as much resolution. A summary of these data sets can be found in Table 1.
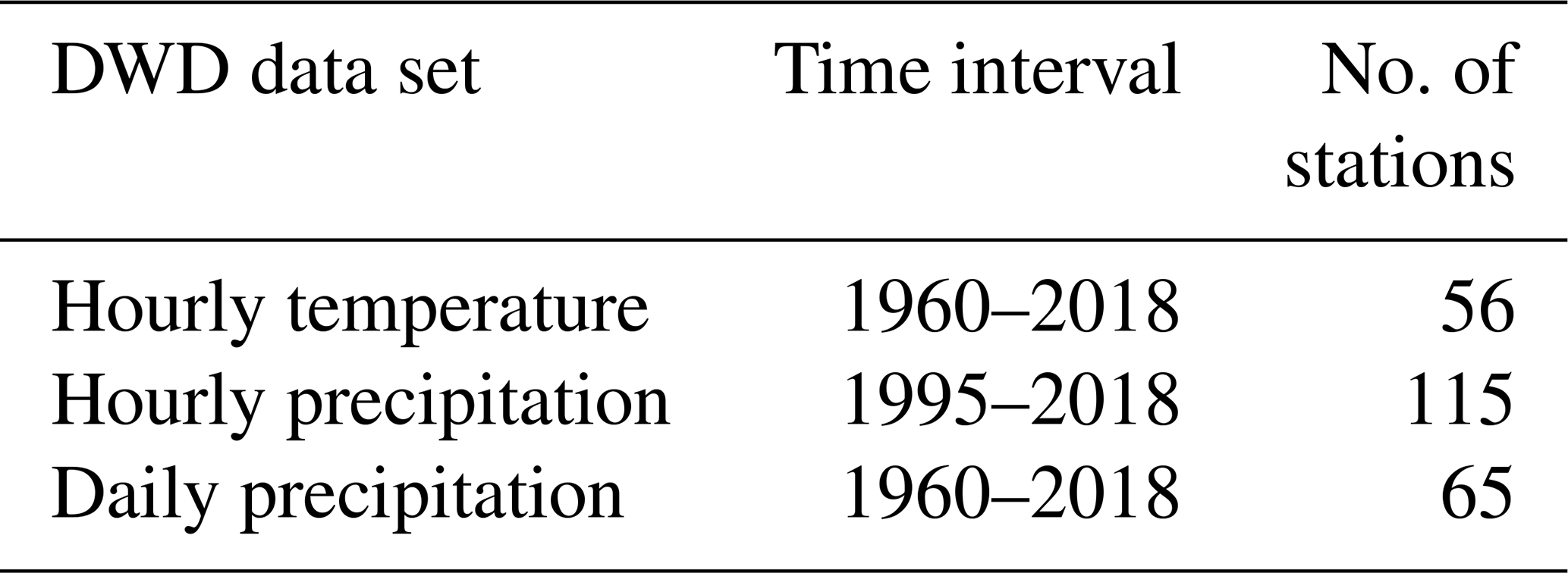
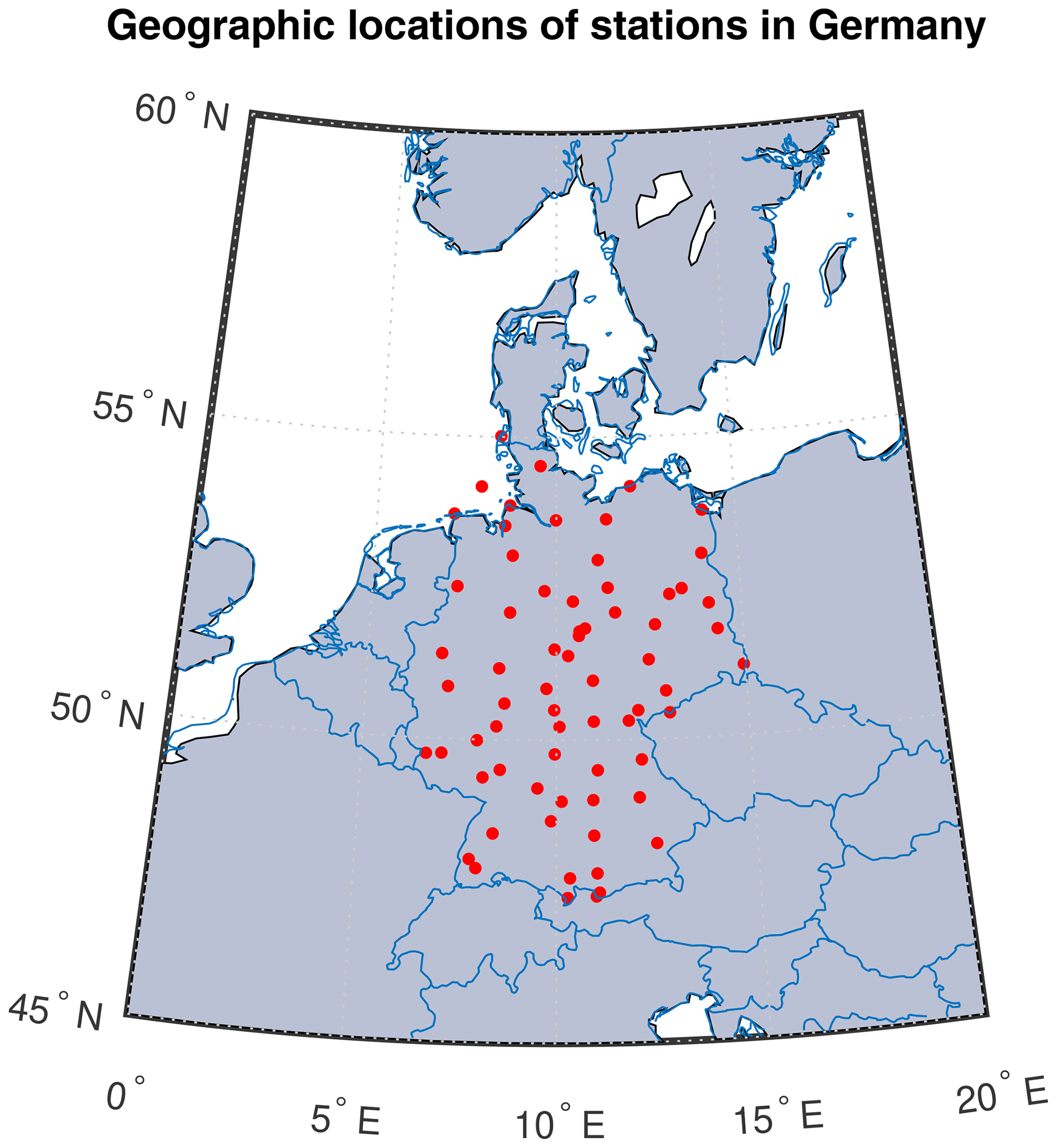
Figure 1Geographic locations of 68 stations used in regional clustering and modeling of temperature extremes.
The time interval from 1960 to 2018 provides a general representation of all climatology in Germany and a reasonable quantity of extreme values for modeling. For information on station locations used in this analysis, see Fig. 1; detailed station location and identification information can be found in Table A1.
Quality control was performed by the DWD CDC with details provided in Kaspar et al. (2013). We remark that all values used in this analysis passed this preprocessing procedure. These data are not detrended to account for the urban heat island; however, we do not expect this to affect the quality of this analysis because most stations are located several kilometers outside of major cities. With the transfer from manual to automatic weather recording stations, additional considerations are made while investigating the statistical parameters in these data. Some stations in our subset contain missing values; while there are methods that allow us to replace missing data in the time series, such as linear interpolation and the like, these methods require an a priori assumption on the trend in the time series. Stations containing missing values are removed from extremal analysis; however, they are still used for regional clustering because missing data will not notably affect the algorithm.
2.2 Regional clustering
This section discusses some machine-learning tools used to perform regional clustering by viewing the set of time series, corresponding to our subset of weather stations, as a network. The set of time series can be viewed as a weighted network (in graph form: a set of nodes and edges) where each station is a node. The weighted edge between two nodes is calculated by a similarity measure that relies on the corresponding time series (Fig. 2).

Figure 2Graphical form of the network defined by temperature time series emphasizing the density of the network. Each node represents a station in the network. Each edge represents a positive similarity between two stations. Note that this graph is not complete because low values of similarity (<0.1) are taken to be zero in this analysis.
Given a network, the goal of clustering analysis is to find a partition with high intra-cluster similarity and low inter-cluster similarity; however, solving this system is an np-hard (non-polynomial) problem. Relaxations of this problem can be split into two approaches: (1) maximizing modularity through partitioning algorithms and redefined modularity metrics (Newman, 2006; Duch and Arenas, 2005; Sun et al., 2009; Li et al., 2008; Chen et al., 2018) or (2) minimizing a distance function through spectral clustering, k-means, and the like (Hastie et al., 2008; Luxburg, 2007; Dhillion et al., 2004). Under standard measures of modularity, Li et al. (2008) showed that these two approaches have an equivalence relation: modularity is maximized if and only if the kernel k-means distance is minimized.
The authors in Carney et al. (2019) approach regional clustering of temperature time series using the spectral clustering method equipped with k-means (Luxburg, 2007). Given n time series, each time series is represented by a point in ℝn where the coordinate is given by the corresponding value of similarity to every time series in the network. The goal of this algorithm is then to find hyperplane separations between the clusters in ℝn by minimizing the objective function defined by the sum of the intra-cluster distances. The spectral portion of this algorithm allows for a reduction in the dimension of the system which results in a set of more easily separable clusters in the lower-dimensional space. The advantage of this approach is that it is computationally efficient and reliable provided that the clusters can be linearly separated. Linear separability is rarely the case with larger, dense clusters (such as in this study) where all similarity measures are close in value. Instead, we employ a weighted Gaussian kernel k-means approach. This method provides a more reliable regional clustering of the time series by allowing the separation of the clusters using a nonlinear function at some computational expense. The weights wh are given by eigenvalues λh of a normalized symmetric, positive definite matrix so that all . These weights serve to compress the clusters along coordinates of less importance, in terms of the corresponding eigenvalue, and maintain space along coordinates of most importance . We outline the main ideas of the algorithm here; for a more rigorous explanation we refer the reader to the Appendix A1. We also refer to Wang et al. (2019) for a nice introduction on kernel k-means and Hastie et al. (2008, Sect. 14.5.3) and Luxburg (2007) for more information on the spectral portion of this algorithm.
-
Step 1. Given any matrix of similarities , calculate the normalized Laplacian
where D is the diagonal matrix with entries .
-
Step 2. Calculate the spectrum of L and choose a cutoff ℓ used to create a subspace of eigenvectors Vh for of L corresponding to the first ℓ eigenvalues.
-
Step 3. Calculate the weighted Gaussian kernel
where and are the respective weighted ith and jth row vectors Wi and Wj of the matrix of eigenvectors Vh and s∈ℝ. where .
-
Step 4. Run kernel k-means.
-
Step 4.1. Start with k random partitions Pk.
-
Step 4.2. Compute the centers , where is the mth row vector of the kernel matrix K and card(⋅) is the cardinality function.
-
Step 4.3. Assign to the partition Pk with centroid Ck such that
is minimized.
-
Step 4.4. Recalculate the centroids based on new assignments of .
-
Step 4.5. Repeat assignment until a stable minimum is reached.
-
It is possible that the stable minimum reached is not the global minimum. We run the algorithm for 1000 different initial sets of partitions and choose the cluster associated with the lowest minimized distance. In addition, the number of partitions (clusters) in kernel k-means needs to be assumed a priori. A standard practice is to run the algorithm for different values of k and choose the optimal value as the smallest k corresponding to the greatest decrease in variance. This technique is typically referred to as the “elbow” method Yuan and Yang (2019).
Mutual information has become a more common measurement of similarity in recent literature because it is capable of measuring nonlinear relationships between two time series. For two random variables (or time series) X1 and X2 taking discrete values, mutual information is defined as
where and . Intuitively, mutual information compares the probability distributions of X1 and X2 by measuring their dependence in terms of the joint distribution relative to an assumption of independence. A positive value for Eq. (4) indicates that X1 and X2 are dependent in some sense. On the other hand, it is straightforward to see that Eq. (4) equals zero if X1 and X2 are independent. We may rewrite mutual information in terms of the entropy of X1 and X2 as
with entropy ℋ(X1) defined by
and joint entropy ℋ(X1,X2) given by
This reconstruction provides a natural expression of mutual information in terms of information and allows for the calculation of error under the compression of the continuous time series. As the true probability distributions of the data are unknown, a standard approach to calculating the entropy of the time series is to compress the data into discrete bins which form an approximate uniform distribution. From here, the error on the mutual information can be calculated by comparing the resulting compressed distribution with proportion probabilities to the uniform distribution with equal proportion (Roulston, 1999).
Compressing the time series can result in an obvious loss of information from the system. Following the work of Carney et al. (2019) and Zhang et al. (2018), we perform gradient ascent by varying the end points of the compression interval to maximize the mutual information between each pair of time series. We will refer to this measurement as the maximized mutual information (MMI). This approach should not change the order of estimated error on the mutual information as entropy is maximized on uniform distributions.
We use a normalized version of the maximized mutual information (NMMI),
for the network defined by the temperature time series. Normalized versions of the mutual information can produce better clustering results by allowing the mutual information to be viewed relative to the entropy of the time series. In the case of the precipitation network, we find that normalizing the maximized mutual information causes a large error in the spectral decomposition of the normalized Laplacian. This error is a product of naturally low entropy in all time series causing a large value of NMMI and, hence, a large value of D, so that the values of L become too low for optimal spectral decomposition. For this reason, we use the unnormalized version of the maximized mutual information for the precipitation network. Higher values in the entropy for the temperature time series can be attributed to hourly and annual cycles, resulting in a distribution with less dispersion than that of the precipitation time series.
Mutual information may return a large positive value for negatively correlated variables. In this analysis, we cross reference our clustering outcomes from mutual information and correlation. Summer hourly temperature time series (with the daily cycle removed) for all stations in the network are positively correlated. This is expected because Germany is smaller than the average warm air mass. If we attempt to cluster the network by correlation, we find the minimized Euclidean distance plot loses its structure and no longer provides an obvious value for the number of clusters k. We make two observations: first, the correlation network does not allow for reliable clustering of regional temperature values; and, second, mutual information adds substance to the network.
We remark that mutual information provides a reasonable estimate of similarity in the context of clustering extremes because it compares the probability distributions of the time series to determine their shared information. Recent literature has also introduced measures of similarity defined by the extremal index (EI; Bador et al., 2015). This measure incorporates a comparison of the location and scale parameters from the time series’ corresponding GEVs in the sense that two GEVs with equal shape parameters and differing EIs are equivalent up to a shift of their location and scale parameters (Coles, 2001, Theorem 5.2).
2.3 Local and regional extreme value modeling
The block maximum method is used in this analysis to model the maximum values of the time series (Coles, 2001). In this method, the time series is broken into blocks of a chosen length l so that asymptotic results hold: where M is the length of the time series, the number of maximum values is M∕l. Provided the block maxima are independent and stationary, classical extreme value results ensure that they will converge to a generalized extreme value (GEV) distribution described by a shape k, location μ, and scale σ parameter.
under the requirement . The shape parameter describes the tail behavior of the maximum values and defines the exact probability distribution to which they will converge, Frechét (Type II) for k>0, Weibull (Type III) for k<0, or Gumbel (Type I) for k=0.
When modeling real-world data, it is natural to use maximum likelihood estimation (MLE; Coles, 2001) or the L-moments method (Hosking and Wallis, 1997) to estimate the three parameters of the GEV model. L-moments is a common technique in climate modeling, and its advantage comes from its stability for low quantities of data (Hosking, 1990); however, the limiting distributions of the estimates are unknown, and bootstrapping methods are required to obtain confidence intervals. Moreover, adaptations to the nonstationary model are not well studied. As we have a relatively large pool of data, maximum likelihood estimation is chosen to estimate the parameters and confidence intervals of the GEV distribution. This is done by maximizing the following log-likelihood function for a set of m block maxima:
provided that
Strict independence is not always necessary for convergence of the maxima to the GEV (Lucarini et al., 2016); however, in practice it is common to choose blocks that are “long enough” for independence to be observed. As temperature time series follow a daily cycle, this daily cycle is removed during independence analysis by subtracting the average cycle over all days in the data. Seasonal cycles are not considered as the data were taken only from summer months. Compression is performed on the centralized data vector by assigning +1 to values that increase in the next step, −1 for values that decrease, and 0 for values that stay the same. These quantities are tabulated, and the chi-square test of independence is performed.
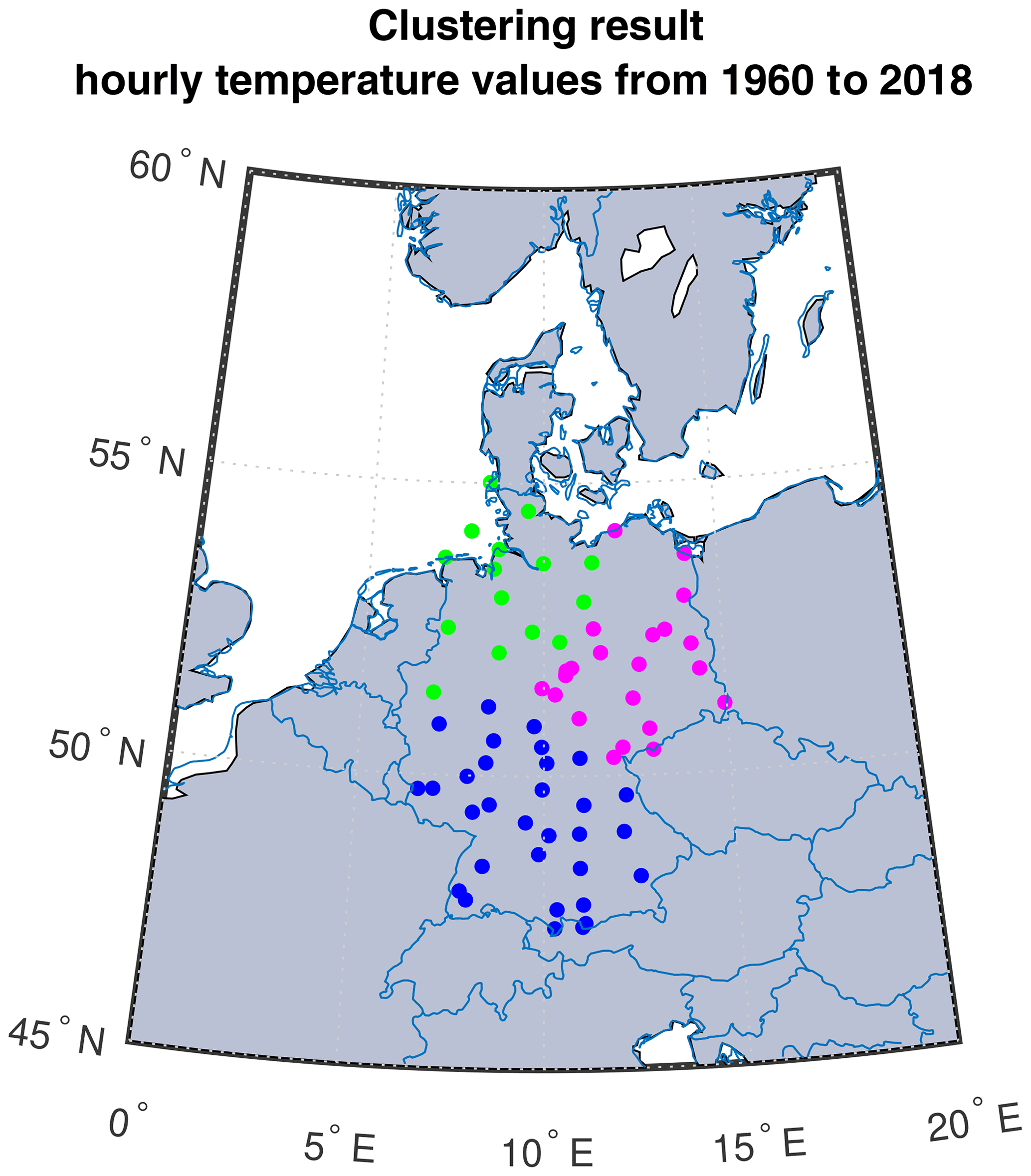
Figure 3Clustering result for the hourly temperature network with similarity defined by NMMI over the time interval from 1960 to 2018.
Stationary assumptions require the location and scale parameters of the maxima to not change in time. We test this assumption using the Mann–Kendall trend test and a mean difference comparison of the time intervals from 1960 to 1990 and from 1991 to 2018 for the temperature maximum at each station where we find evidence of a linear trended location parameter.

Figure 4Clustering result for the (a) daily precipitation amounts network taken from the hourly DWD data set with similarity defined by MMI, and (b) the hourly temperature network with similarity defined by NMMI over the time interval from 1995 to 2018.
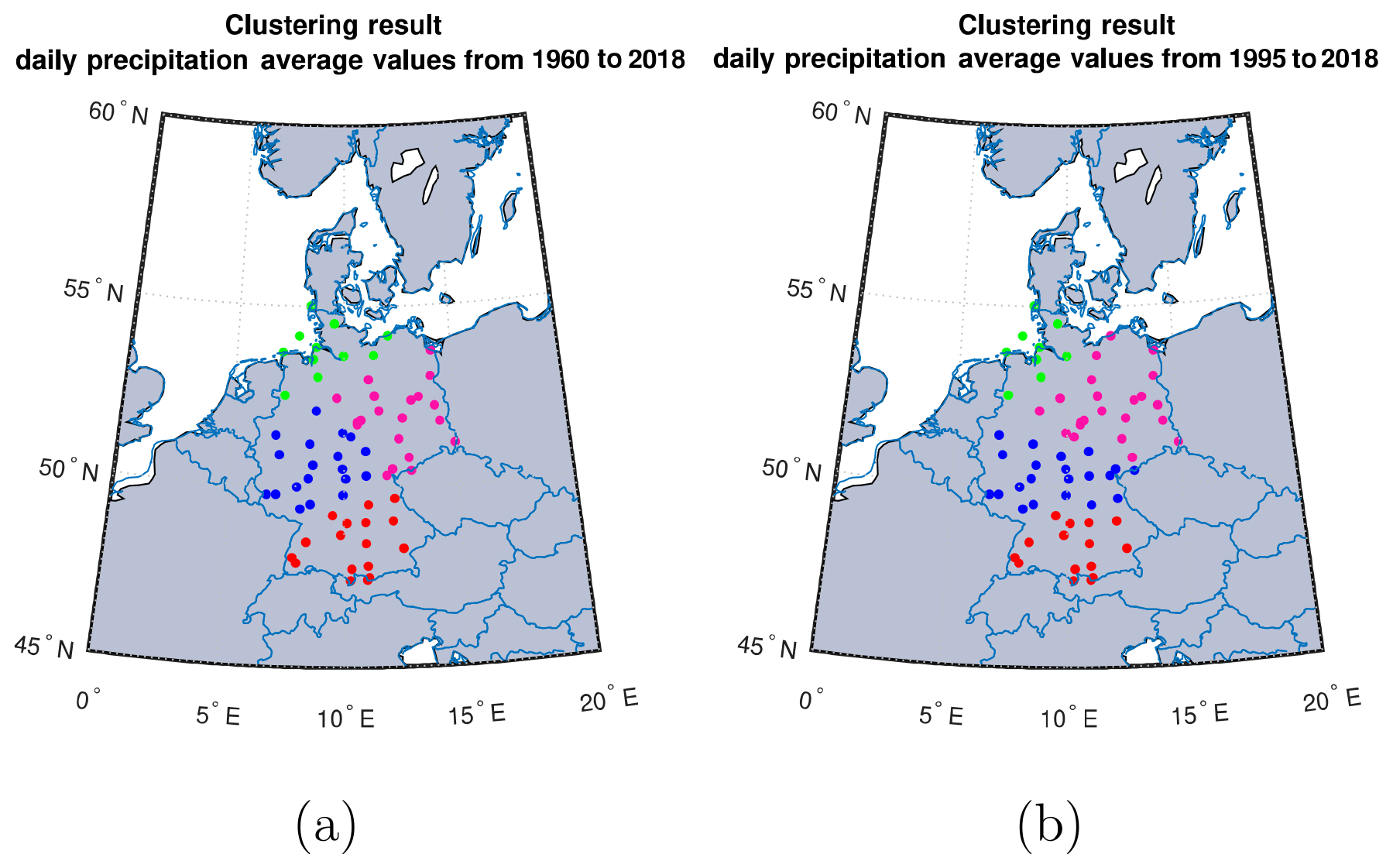
Figure 5Clustering result for the daily precipitation amounts network taken from the daily DWD data set over (a) the time interval from 1960 to 2018 and (b) the time interval from 1995 to 2018 with similarity defined by MMI.
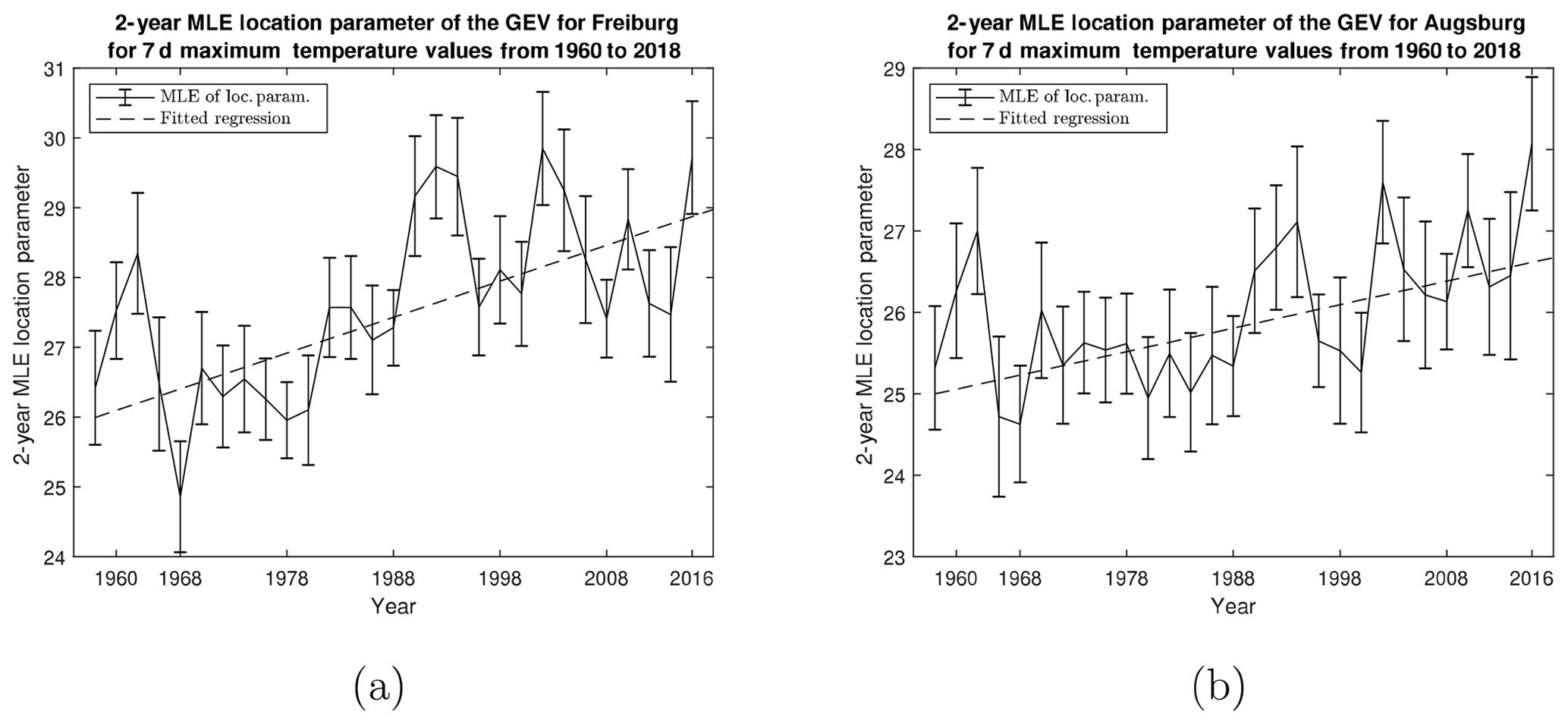
Figure 6Example time plots for the 2-year maximum likelihood estimate of the location parameter with standard error bars for weekly maximum temperature values taken from (a) Freiburg with fitted regression and (b) Augsburg with fitted regression (where t is 2-years). Time plots from other stations are similar and can be attributed to the previously mentioned correlations between stations throughout Germany.
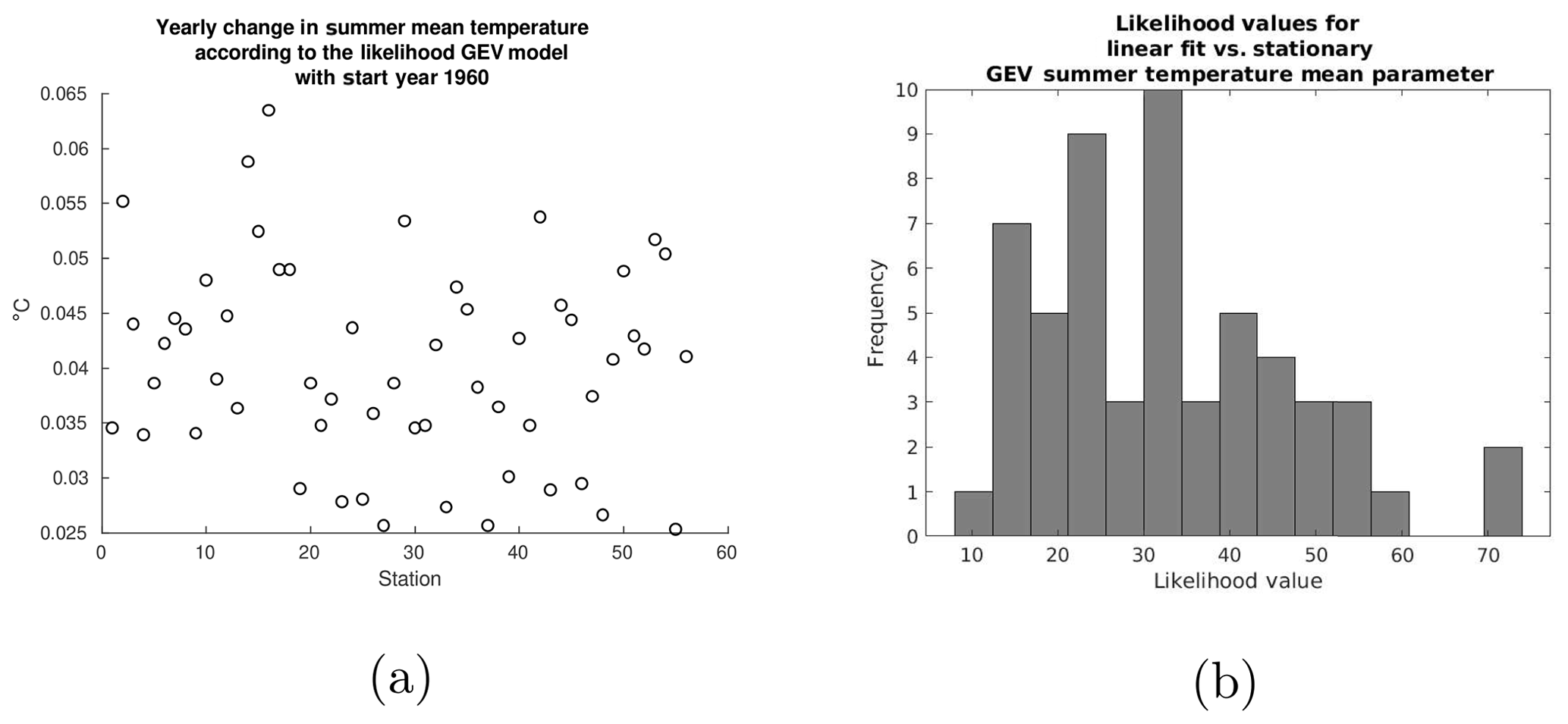
Figure 7(a) Scatter plot of the yearly change in the temperature mean according to the likelihood GEV model for all stations. (b) Likelihood values comparing the linear fit of the summer temperature mean to that of a stationary mean. All likelihood values surpass the chi-square value of .
Finally, we perform a likelihood-ratio test on the stationary and nonstationary model equipped with a linear time-dependent location parameter . Estimates of the parameters of the nonstationary GEV model were obtained by maximum likelihood estimation of the following log-likelihood function:
where ti is the index of a block over which the maxima is taken.
The likelihood-ratio test compares the final log-likelihood values ℒ1 and ℒ0 of the nonstationary model ℳ1 and the stationary model ℳ0 via the “deviance statistic”:
where 𝒟∼χ2(1). To test whether the resulting nonstationary model fits the data, we transform the original time series of maximum values, Zt by
It is known that follows a stationary Gumbel distribution with μ=0 and σ=1 (Coles, 2001). We perform the Anderson–Darling goodness of fit test on under these assumptions for every station in this analysis.
Regional models are created by formulating a mixed GEV distribution from all of the stations in a regional cluster. The mixed GEV distribution is given by
where N is the number of stations in the regional cluster. This distribution describes the probability of an observed temperature extreme occurring in the regional population defined by the cluster of subpopulations (stations) given an equal probability of sampling from any subpopulation in the regional population. We refer to Yoon et al. (2013) for an example of mixed GEV distributions; however, we remark that fitting results are not required in our context because subpopulations are known.
3.1 Regional clustering results
As discussed in Sect. 2.2, we compute the maximized mutual information between each pair of stations represented by their corresponding hourly temperature time series from 1960 to 2018. Throughout this analysis, all error for maximized mutual information is on the order of 10−5. Outcomes of our clustering algorithm applied to the maximized mutual information matrix suggest that Germany has three (k=3) distinct climate regions located in (roughly) the northwest, the northeast, and the south (Fig. 3).
To test for time invariance of the clusters, we apply the algorithm to the intervals from 1960 to 2000, from 1970 to 2010, and from 1980 to 2018. Resulting clusters are equivalent for all three time intervals.
For further investigation, we consider clusters obtained by maximizing the mutual information between pairs of stations represented by their corresponding daily precipitation amounts. Daily precipitation amounts for this analysis are taken from the same hourly recording data set as the temperature data. Precipitation data in this set are only available for the time period from 1995 to 2018. All available data over the period from 1995 to 2018 are used to show the robustness of the regional clusters; however, these data are not used in the final regional cluster analysis of temperature extremes. Hourly precipitation values are summed over each 24 h period and the resulting time series is used to compute the MMI matrix. Clustering results suggest the network of daily precipitation amounts is regionally equivalent to that of hourly temperature (Fig. 4).
For added measure, we consider the daily precipitation amounts taken from the daily DWD CDC set which have values over the same time period (1960–2018) as our temperature data set.
Results from our clustering algorithm show preference for four (k=4) regional clusters over Germany. This fourth cluster is created from a splitting of the southern cluster (Fig. 5). The period from 1995 to 2018 is checked for this data set with similar results. An investigation into the raw data shows slight discrepancies when compared with that of the summed hourly precipitation data which may be the result of differences in the time of recording.

Figure 8Scatter plot illustrating the difference in mean summer temperature taken over the period from 1960 to 1990 (x axis) and from 1991 to 2018 (y axis) with standard error bars. All values and standard error bars are located above the identity.
3.2 Local and regional extreme value modeling results
For the remaining analysis, we define an extreme (or maximum) value of the temperature time series as the maximum taken over data blocks of 7 d (168 data points). We find independence over almost all blocks at the α=0.05 significance level. The quantity of blocks that do not return independence are less than 5 % and can be attributed to the type I error of the test.

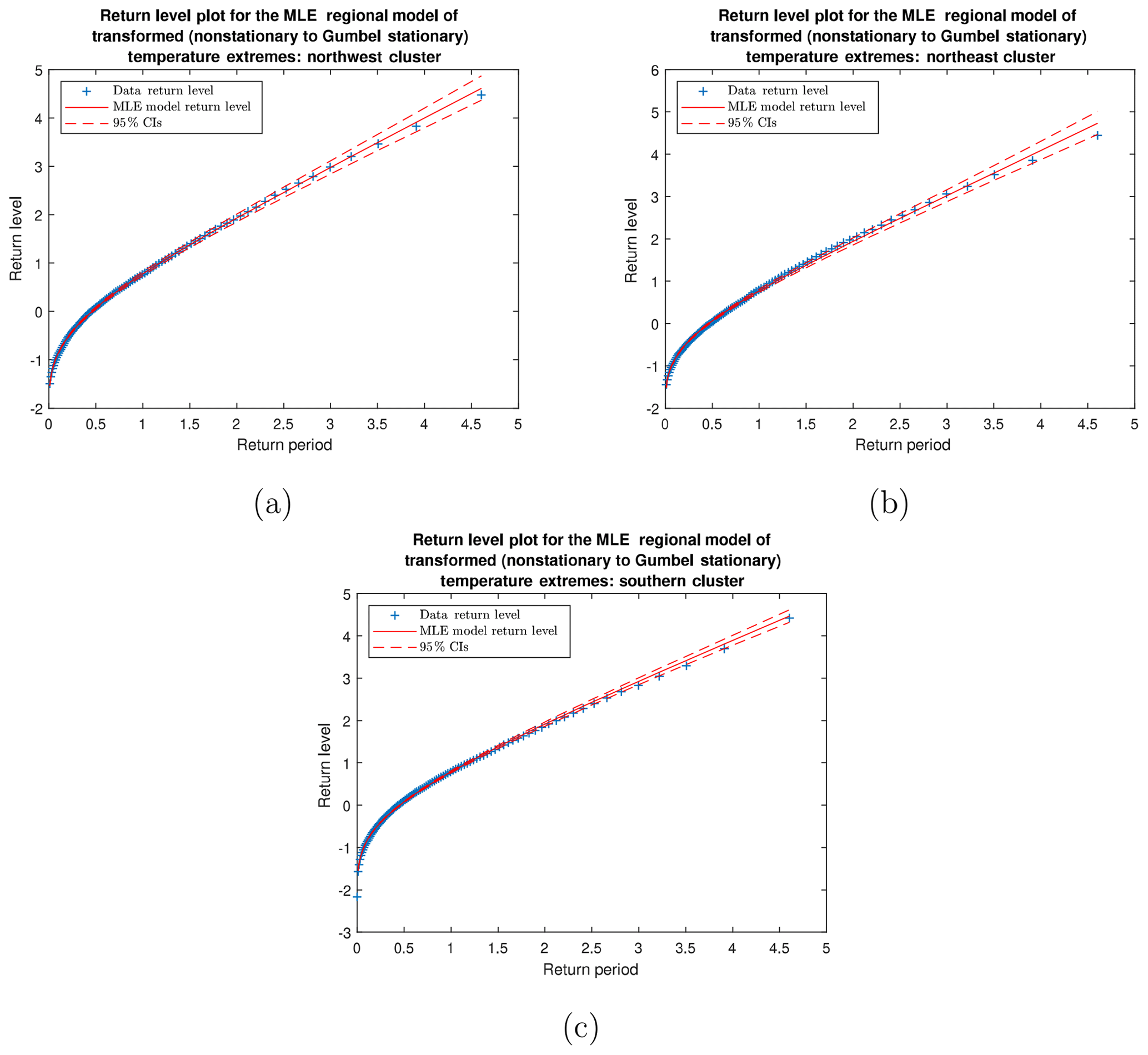
Figure 9Return level plots comparing the parametric mixed GEV distribution with confidence intervals and actual mixed temperature maxima for the (a) northwest, (b) northeast, and (c) south clusters. These plots emphasize the regional model's fit to the pooled data.
Recall from Sect. 2.3 that fitting a GEV model to the maximum values in a time series requires stationarity of the maximum values, e.g., their location and scale parameters do not change in time. We first test this assumption using the Mann–Kendall trend test on the 2-year (m=24 block maxima) maximum likelihood estimate of the location and scale parameters for weekly summer temperature extremes with the p values indicating that a significant trend (α=0.05) exists for the location parameter and no trend exists for the scale parameter for all stations. We choose 2 years (m=24) of maximum values because this exceeds the minimum sample size requirement for estimating the mean while providing enough data to investigate the trend. Low quantities of block maxima produce larger standard errors on the location parameter. As a way of obtaining additional information to make conclusions regarding the trend, we perform a mean-difference test on the maximum likelihood estimate of the location parameter over the time intervals from 1960 to 1990 and from 1991 to 2018 (m≈373 block maxima per interval) with the alternative hypothesis μ1991–2018>μ1960–1990. As the MLE location parameter is asymptotically normal, we use the 95 % confidence intervals to calculate the standard error used in the mean-difference test. We find that this difference is significant (at the α=0.05 significance level) for every station; see Fig. 7 for these results. We also refer the reader to Table A2 for more detailed information. We note that, due to the variability in the location parameter described earlier, low p values from the Mann–Kendall test imply low p values for the mean-difference test, whereas the converse is not true. Time plots are also evaluated as a superficial method of determining whether this trend is the result of a single change-point in the 1990s (Fig. 6). These plots show a continued upward trend, suggesting that this phenomenon is not the result of manual/automatic instrumental change.
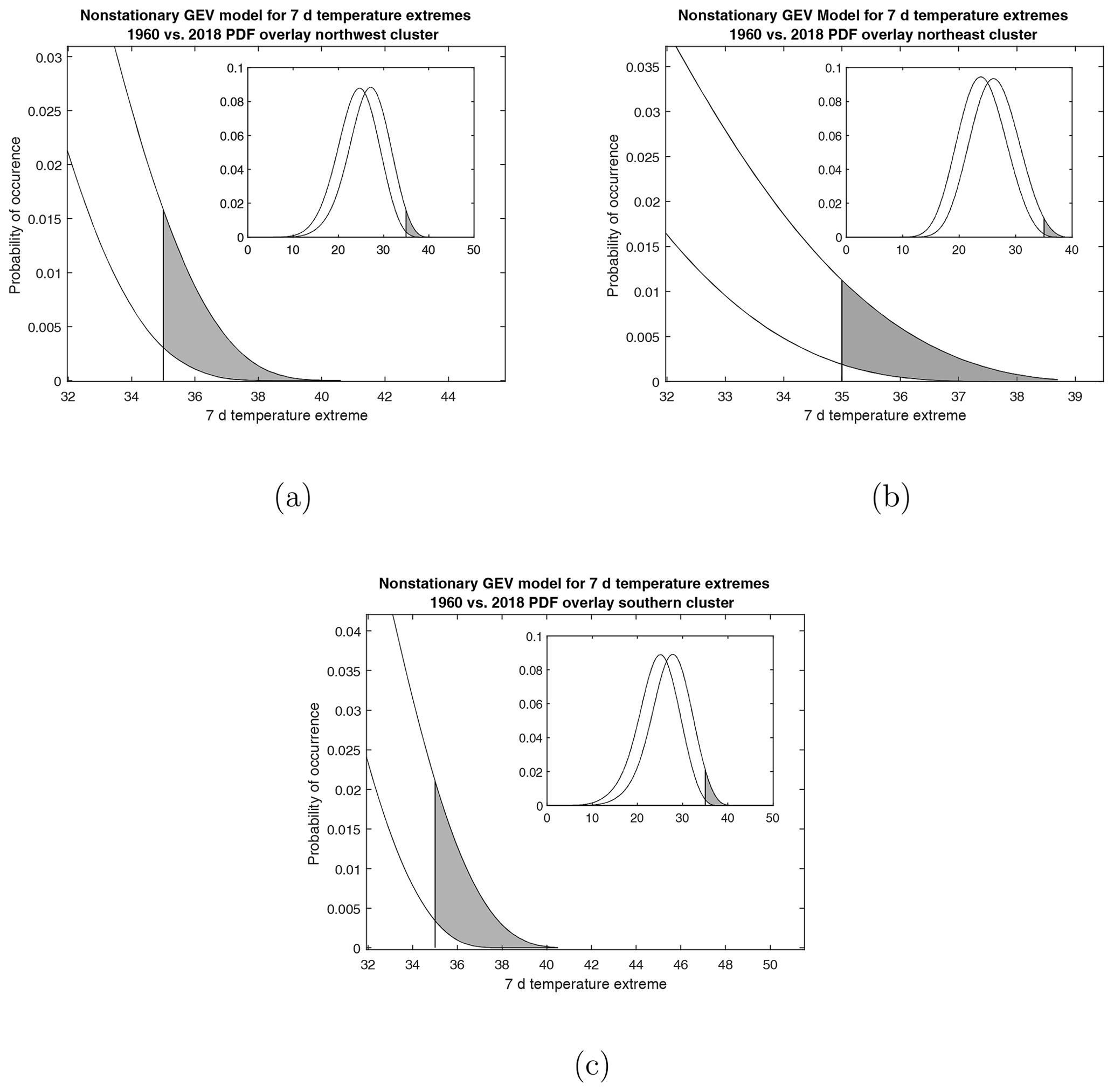
Figure 10Nonstationary generalized extreme value model overlay of 1960 and 2018 weekly temperature extremes for the (a) northwest (b) northeast, and (c) south regional clusters. The shaded region indicates the probability of observing a weekly extreme higher than 35 ∘C.
Results from these tests provide justification for considering nonstationary modeling of the weekly summer temperature extremes. We use maximum likelihood estimation of the log-likelihood function equipped with a linear trended location parameter to generate the nonstationary GEV model for every station in the data set. We compare these results with the stationary model using the likelihood ratio test, and we find that the nonstationary model provides a significant (α=0.05) improvement over the stationary model for every station; see Fig. 8 for these results. We also refer the reader to Table A3 for more detailed information.
We form regional GEV models using the mixed GEV distribution described by Eq. (14). Stations located at high altitude, including Zugspitze and (the mountains near) Görlitz, were removed from the regional model. These stations have location parameter values that are further than 2 standard deviations away from the regional location parameter. This deviation causes issues with the modality and accuracy of regional temperature extreme probability estimation. When creating regional models of extremes, care needs to be taken regarding the homogeneity of the region in terms of the shape parameter. This is especially important for regional models of extremes where local phenomena are observed. We remark that the mixed GEV distribution has been used to describe regional dynamics with unknown local phenomena through likelihood estimation (Yoon et al., 2013); however, this method is not relevant for our purposes because the subpopulation GEVs (station GEVs) are known and the shape parameters for temperature maxima from each station are nearly equivalent.
To determine how well the regional models represent the pooled time series, we first transform the time series of maxima for each station into a stationary Gumbel distribution using Eq. (13) and perform the Anderson–Darling goodness of fit test on the transformed maxima under the null hypothesis that these data follow a stationary Gumbel distribution with μ=0 and σ=1. We find that all stations follow the null hypothesis at the α=0.05 significance level. Using Eq. (14), we create a transformed (stationary) regional model from the transformed time series that is also expected to follow a Gumbel distribution of μ=0 and σ=1. We perform maximum likelihood estimation on the transformed regional models to test this expectation. All 95 % confidence intervals contain the values μ=0, σ=1, and k=0 (see Table 2). This transformation allows us to create return level plots for the regional model (Fig. 9). Our results suggest that the return levels obtained for the transformed regional model fit the transformed time series. We remark that these return level plots can only be used in model diagnostics to ensure that the regional model is a good representation of the pooled data. Return times for probabilities of temperature maxima exceeding the threshold must be derived from the mixed GEV with a fixed time value.
We use the MLE parameters k, μ(t), and σ of the nonstationary GEV models for the mixed GEV regional distribution with fixed t related to the beginning of 1960 and the beginning of 2018. Comparing these models shows an increase in the probability of observing maximum weekly summer temperatures greater than 35 ∘C of up to 6 times for 2018 compared with 1960 (Fig. 10, Table 3). We remark that the largest difference in the probability of observing an extreme temperature event occurs in the southern cluster, which is likely the result of ocean regulation on the warming trend in the northern clusters (Pörtner et al., 2020).
Table 3Regional tail probability estimates (in units of occurrences per year) for weekly temperature extremes above 35 ∘C.
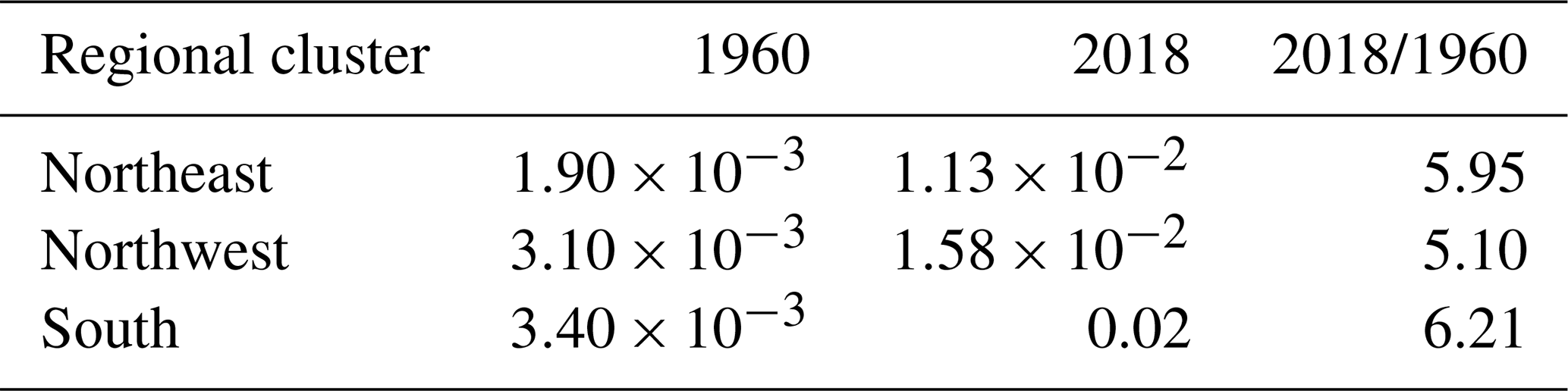
In this analysis, we expand on the work of Carney et al. (2019) by considering a more dense set of networks and adding a weighted kernel k-means approach to the algorithm. This addition allows for more reliable clustering where the k-means method was shown to fail. We find regional clusters for weather stations throughout Germany by defining a network based on their corresponding summer, hourly temperature values. The resulting clusters are not only time invariant but are shared by the network defined by the corresponding daily precipitation amounts. The addition of more stations to the network does not radically change the clustering outcome. Shared clusters could reflect an underlying relationship between temperature and precipitation dynamics. This result is nontrivial because similarity at the station level does not generalize in an obvious way due to the numerous external factors that affect regional weather. We remark that the clustering equivalence does not (necessarily) indicate that temperature and precipitation move together, rather that their individual networks contain relationships between stations within equivalent spacial regions.
We use the clusters we obtain from our algorithm to create regional models of the weekly summer temperature extremes. We find significant increasing linear trends in the location parameter of these models and a preference for nonstationary modeling for all stations in the network. Regional nonstationary models are created by defining a mixed nonstationary GEV distribution from likelihood results. Return time plots are used to validate the results. Regional distribution models reveal an increase in the probability of observing a weekly summer temperature maximum above 35 ∘C of up to 6 times for 2018 compared with 1960.
In future work, we will consider more complicated networks defined by both temperature and precipitation values, simultaneously. We plan to use these results to form joint probability densities of temperature and precipitation extremes. Viewing the data in this way will allow us to make conclusions about the conditional extreme probabilities. We are also interested in determining whether these clusters are seasonally dependent or consistent throughout the year.
A1 A spectral weighted kernel k-means algorithm
The similarity matrix Si,j in this study is transformed into the normalized Laplacian given by
Spectral decomposition is performed on L, and a matrix is formed with columns given by the first h eigenvectors of L. As the Laplacian is normalized, the first h eigenvalues represent the eigenvectors carrying the most information from the network (represented by the Laplacian matrix). The corresponding subspace made of the span of is the reduced dimensional network that approximates the true network well. The rows of this matrix correspond to the h-dimensional projections of the input vectors (e.g., the h-dimensional projections of the rows of the similarity matrix). Each row gives a point representation x∈ℝh to the stations in the network. The goal of the next step in the algorithm is to find divisions that create clusters of these points in ℝh.
Kernel k-means allows for separation of clusters by a nonlinear function. This is done by taking a nonlinear mapping of each input vector x∈ℝh into a higher-dimensional (possibly infinite) feature space. Once in the feature space, the goal of clustering is to find partitions that minimize the objective function now given by
where Pk is the kth partition, and i∈Pk indicates the index assigned to Pk. Schölkopf et al. (1998) defined the “kernel trick” by recognizing that ϕ can be viewed as a function on the Hilbert space ℱ equipped with the inner product norm . This allows us to redefine the objective function
in terms of a kernel . Now, we may minimize the objective function without having to explicitly compute the feature vectors ϕ(x). Choosing K(xi,xj) as the Gaussian kernel used in this analysis, given by
ensures some universality in the sense that any function required to separate the cluster can be approximated arbitrarily well by a function of the kernel form. The weighted Gaussian kernel is calculated by
where ; here, is the vector of h first eigenvalues of L and . The values of w represent the amount of information (given by the associated eigenvalue of L) carried by a component of x∈ℝh. By using w to weight the input vectors of the kernel, we are able to tighten clusters along coordinates with the least amount of information, or , while maintaining distance along coordinates with the most amount of information, or .
Table A2Location trend results for the hourly temperature time series. pMEAN DIFF HA: μ1960–1990<μ1991–2018 and pMK HA: trend.
Table A3MLE nonstationary models for temperature maxima. scale σ, shape k, location , and likelihood D parameters. Here, t is 1 week.
The hourly temperature and precipitation data sets and the daily precipitation data set are freely available from the DWD CDC website: https://www.dwd.de/EN/climate_environment/cdc/cdc_node.html (DWD CDC, 2018a, b, 2019). The code used to perform the methods outlined in the paper was written in MATLAB and R using a combination of pre-built and newly created functions. For access to this code, please contact the corresponding author.
The majority of the work for this study was performed by MC with heavy guidance from HK. Both authors worked closely together on this analysis and held regular discussions on all aspects of this paper.
The authors declare that they have no conflict of interest.
The authors thank Kevin Bassler for helpful discussions and the Deutscher Wetterdienst Climate Data Center for the hourly and daily data sets used in this analysis. The authors are also grateful to Jakob Zscheischler and the anonymous reviewer for their helpful comments and suggestions.
This paper was edited by William Hsieh and reviewed by Jakob Zscheischler and one anonymous referee.
Azencott, R., Muravina, V., Hekmati, R., Zhang, W., and Paldino, M.: Automatic clustering in large sets of time series, Contributions to Partial Differential Equations and Applications, Comput. Meth. Appl. Sci., 47 65–75, 2018. a
Bador, M., Naveau, P., Gilleland, E., Castellá, M., and Arivelo, T:. Spacial clustering of summer temperature maxima from the CNRM-CM5 climate model ensembles and E-OBS over Europe, Weather and Climate Extremes, 9, 17–24, https://doi.org/10.1016/j.wace.2015.05.003, 2015. a
Balvanera, P., Siddique, I., Dee, L., Paquette, A., Isbell, F., Gonzalez, A., Byrnes, J., O'Connor, M., Hungate, B., and Griffin, J.: Linking biodiversity and ecosystem services: current uncertainties and the necessary next steps, BioScience, 64, 49–57, 2013. a
Bartos, M., Chester, M., Johnson, N., Gorman, B., Eisenberg, D., Linkov, I., and Bates, M.: Impacts of rising air temperatures on electric transmission ampacity and peak electricity load in the United States Environ. Res. Lett., 11, 114008, https://doi.org/10.1088/1748-9326/11/11/114008, 2016. a
Bellard, C., Bertelsmeier, C., Leadley, P., Thuiller, W., and Courchamp, F.: Impacts of climate change on the future of biodiversity, Ecol. Lett., 15 367–377, 2012. a
Brown, S. J., Caesar, J., and Ferro, C. A. T.: Global changes in extreme daily temperature since 1950, J. Geophys. Res., 113, D05115, https://doi.org/10.1029/2006JD008091, 2008. a
Burillo, D.: Effects of Climate Change in Electric Power Infrastructures, Power System Stability, IntechOpen, 5, https://doi.org/10.5772/intechopen.82146, 2019. a
Carney, M., Azencott, R., and Nicol, M.: Nonstationarity of summer temperature extremes in Texas, Int. J. Climatol., 40, 620–640, https://doi.org/10.1002/joc.6212, 2019. a, b, c, d, e
Caroni, C. and Panagoulia, D.: Non-stationary modelling of extreme temperatures in a mountainous area of Greece, REVSTAT, 14, 217–228, 2016. a
Chen, T., Singh, P., Bassler, K.: Network community detection using modularity density measures, J. Stat. Mech., 2018, 053406, https://doi.org/10.1088/1742-5468/aabfc8, 2018. a
Cheng, L., AghaKouchak, A., Gilleland, E., and Katz, R. W.: Non-stationary Extreme Value Analysis in a Changing Climate, Climatic Change, 2, 353–369, https://doi.org/10.1007/s10584-014-1254-5, 2014. a
Christidis, N., Stott, P., and Brown, S.: The role of human activity in the recent warming of extreme warm daytime temperatures, J. Climate, 24, 1922–1930, 2011. a, b
Christidis, N., Jones, G. S., and Stott, P. A.: Dramatically increasing chance of extremely hot summers since the 2003 European heatwave, Nat. Clim. Change, 5, 46–50, 2015. a
Coles, S.: An Introduction to Statistical Modeling of Extreme Values, Springer, 2001. a, b, c, d, e
Cover, T. and Thomas, J.: Elements of Information Theory, John Wiley and Sons, 1991.
Dhillion, I., Guan, Y., and Kulis, B.: Kernel k-means, spectral clustering and normalized cuts, Conference on Knowledge Discovery and Data Mining (KDD) 22–25 August, Seattle, Washingtion, USA, 2004. a
Duch, J. and Arenas, A.: Community detection in complex networks using extremal optimization, Phys. Rev. E, 72, 027104, https://doi.org/10.1103/PhysRevE.72.027104, 2005. a, b
DWD Climate Data Center (CDC): Historical hourly station observations of 2m air temperature and humidity for Germany, version v006, available at: https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/air_temperature/historical/ (last access: 13 June 2019), 2018a. a, b
DWD Climate Data Center (CDC): Historical hourly station observations of precipitation for Germany, versionv006, available at: https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/hourly/precipitation/historical/ (last access: 26 June 2019), 2018b. a
DWD Climate Data Center (CDC): Historical daily precipitation observations for Germany, version v007, available at: https://opendata.dwd.de/climate_environment/CDC/observations_germany/climate/daily/more_precip/historical/, last access: 5 August 2019. a
Erkwurzel, B., Boneham, J., Dalton, M. W., Heede, R., Mera, R. J., Allen, M. R., and Frumhoff, P. C.: The rise in global atmospheric CO2, surface temperature, and sea level from emissions traced to major carbon producers, Climactic Change, 144, 579–590, 2017. a
Finkel, J. and Katz, J. I.: Changing world extreme temperature statistics, Int. J. Climatol., 38, 2613–2617, 2018. a
Gao, M. and Zheng, H.: Nonstationary extreme value analysis of temperature extremes in China, Stoch. Env. Res. Risk A., 32, 1299–1315, 2018. a
Gasparrini, A., Guo, Y., Sera, F., Vicedo-Cabrera, A. M., Huber, V., Tong, S., Coelho, M. S. Z. S., Saldiva, P. H. N., Lavigne, E., Correa, P. M., Ortega, N. V., Kan, H., Osorio, S., Kyselý, J., Urban, A., Jaakkola, J. J. K., Ryti, N. R. I., Pascal, M., Goodman, P. G., Zeka, A., Michelozzi, P., Scortichini, M., Hashizume, M., Honda, Y., Hurtado-Diaz, M., Cruz, J. C., Seposo, X., Kim, H., Tobias, A., Iñiguez, C., Forsberg, B., Åström, D. O., Ragettli, M. S., Guo, Y. L., Wu, C., Zanobetti, A., Schwartz, J., Bell, M. L., Dang, T. N., Van, D. D., Heaviside, C., Vardoulakis, S., Hajat, S., Haines, A., and Armstrong, B.: Projections of temperature-related excess mortality under climate change scenarios, The Lancet Planetary Health, 1, E360–E367, 2017. a
Guimera, R. and Amaral, L. N.: Functional cartography of complex metabolic networks, Nature, 433, 895–900, 2005. a
Hamdi, Y., Duluc, C. M., and Rebour, V.: Temperature extremes: estimation of non-stationary return levels and associated uncertainties, Atmosphere, 9, 129, https://doi.org/10.3390/atmos9040129, 2018. a, b
Hansen, J., Ruedy, M., Sato, M., and Lo, K.: Global surface temperature change, Rev. Geophys., 48, RG4004, https://doi.org/10.1029/2010RG000345, 2010. a
Hansen, J., Sato, M., and Ruedy, R.: Perception of climate change, P. Natl. Acad. Sci. USA, 109, E2415–E2423, 2012. a
Hasan, H., Salam, N., and Adam, M.: Modelling extreme temperature in Malaysia using generalized extreme value distribution, Int. J. Math. Comput. Sc., 7, https://doi.org/10.5281/zenodo.1080273, 2013. a
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning: Data Mining, Inference and Prediction, 2nd Edn., Springer, 2008. a, b, c
Hosking, J. R. M.: L-moments: Analysis and Estimation of Distributions using Linear Combinations of Order Statistics, J. R. Stat. Soc. B., 52, 105–124, 1990. a
Hosking, J. R. M. and Wallis, J. R.: Regional Frequency Analysis: An approach based on L-moments, Cambridge University Press, 1997. a
Kaspar, F., Müller-Westermeier, G., Penda, E., Mächel, H., Zimmermann, K., Kaiser-Weiss, A., and Deutschländer, T.: Monitoring of climate change in Germany – data, products and services of Germany's National Climate Data Centre, Adv. Sci. Res., 10, 99–106, https://doi.org/10.5194/asr-10-99-2013, 2013. a
Kosanic, A., Kavcic, I., van Kleunen, M., and Harrison, S.: Climate change and climate change velocity analysis across Germany, Sci. Rep., 9, https://doi.org/10.1038/s41598-019-38720-6, 2019. a
Kyselý, J.: Temporal fluctuations in heat waves at Prague–Klementinum, the Czech Republic, from 1901–97, and their relationships to atmospheric circulation, Int. J. Climatol., 22, 33–50, 2002. a
Li, Z., Zhang, S., Wang, R.-S., Zhang, X.-S., and Chen, L.: Quantitative function for community detection, Phys. Rev. E, 77, 036109, https://doi.org/10.1103/PhysRevE.77.036109, 2008. a, b
Lucarini, V., Faranda, D., Freitas, A. C. M., Freitas, J., Tobias, K., Holland, M., Nicol, M., Todd, M., and Vaienti, S.: Extremes and Recurrence in Dynamical Systems, Wiley, 2016. a
Luxburg, U.: A Tutorial on Spectral Clustering, Stat. Comput., 17, 395–416, https://doi.org/10.1007/s11222-007-9033-z, 2007. a, b, c, d
Newman, M. E. J.: Modularity and community structure in networks, P. Natl. Acad. Sci. USA, 103, 8577–8582, 2006. a, b
Pörtner, H.-O., Roberts, D.C., Masson-Delmotte, V., Zhai, P., Tignor, M., Poloczanska, E., Mintenbeck, K., Nicolai, M., Okem, A., Petzold, J., Rama, B., and Weyer, N.: IPCC, 2019: Summary for Policymakers, IPCC Special Report on the Ocean and Cryosphere in a Changing Climate, in press, 2020. a
Rahmstorf, S. and Coumou, D.: Increase of extreme events in a warming world, P. Natl. Acad. Sci. USA, 108, 17905–17909, 2011. a
Roulston, M.: Estimating the errors on measured entropy and mutual information, Physica D, 125, 285–294, 1999. a
Schär, C., Vidale, P., Lüthi, D., Frei, C., Häberli, C., Liniger, M., and Appenzeller, C.: The role of increasing temperature variablility in European summer heatwaves, Nature, 427, 332–336, 2004. a
Schölkopf, B., Smola, A., and Müller, K.-R.: Nonlinear component analysis as a kernel eigenvalue problem, Neural Comput., 10, 1299–1319, 1998. a
Sun, Y., Danila, B., Josíc, K., and Bassler, K.: Improved community structure detection using modified fine-tuning strategy, Europhysics Letters Association, 86, 2, https://doi.org/10.1209/0295-5075/86/28004, 2009. a
Thornton, H. E., Hoskins, B. J., and Scaife, A. A.: The role of temperature in the variability and extremes of electricity and gas demand in Great Britain, Environ. Res. Lett., 11, 11, https://doi.org/10.1088/1748-9326/11/11/114015, 2016. a
Tomczyk, A. and Sulikowska, A.: Heat waves in lowland Germany and their circulation-related conditions, Meterology and Atmospheric Physics, 130, 499–515, 2018. a
Treviño III, S., Sun, Y., Cooper, T., and Bassler, K.: Robust detection of hierarchical communities from Escherichia coli gene expression data, PLOS Comput. Biol., 8, E1002391, https://doi.org/10.1371/journal.pcbi.1002391, 2012. a
Wang, S., Gittens, A., and Mahoney, M.: Scalable Kernel K-Means Clustering with Nyström Approximation: Relative-Error Bounds, J. Mach. Learn. Res., 20, 1–49, 2019. a
Wergen, G. and Krug, J.: Record-breaking temperatures reveal a warming climate, Europhys. Lett., 92, 3, https://doi.org/10.1209/0295-5075/92/30008, 2010. a
Yoon, P., Kim, T.-W., and Yoo, C.: Rainfall frequency analysis using a mixed GEV distribution: a case study for annual maximum rainfalls in South Korea, Stoch. Env. Res. Risk A., 27, 1143–1153, 2013. a, b
Yuan, C. and Yang, H.: Research on K-Value Selection Method of K-Means Clustering Algorithm, Mutlidisciplinary Scientific Journal, 2, 226–235, https://doi.org/10.3390/j2020016, 2019. a
Zhang, W., Muravina, V., Azencott, R., Chu, Z., and Paldino, M.: Mutual information better quanitfies brain network architecture in children with epilepsy, Comput. Math. Methods M., 2018, 6142898, https://doi.org/10.1155/2018/6142898, 2018. a
Zscheischler, J., Mahecha, M., and Harmeling, S.: Climate Classifications: the Value of Unsupervised Clustering, Procedia Comput. Sci., 9, 897–906, 2012. a